■はじめに
この記事は、「Houdini Advent Calendar 2018 – 8日目 」の記事です。
■対象読者
・Houdini初級~中級者
■リファクタリングとはなにか?
リファクタリング (refactoring) とは、コンピュータプログラミングにおいて、プログラムの外部から見た動作を変えず にソースコードの内部構造を整理する ことである。また、いくつかのリファクタリング手法の総称としても使われる。ただし、十分に確立された技術とはいえず、また「リファクタリング」という言葉に厳密な定義があるわけではない。(Wikipediaより抜粋 )
※ここでいう「プログラムの外部から見た動作を変えず」というのは、リファクタリング前後で、リファクタリングする対象が行う処理の結果を変えないという意味です。
■Houdiniでのリファクタリング
Houdiniでの作業はプログラミング色が強く、ノードネットワークを組み立てることはプログラミングすることそのものと言えます。
■リファクタリングのメリット
リファクタリングにより、ノードネットワークの構造を整理することができ、結果として以下のようなメリットが得られます。
・ノードネットワークを局所的/全体的に理解しやすくなる・理解しやすく整理された形で新たなノードネットワークを作れるようになる
■手法ごとの具体的な方法
□名前の変更
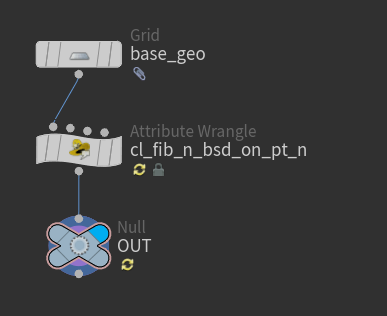
ノード名、パラメータ名、アトリビュート名、Wrangleの変数名など、各種「名前付きの要素」 を、誰が見てもわかりやすい形にリネームします。
・名前のプリフィクス(接頭辞)について
set_, del_ などの部分だけでノードごとの基本的な動作が伝わります その要素が何を行うものであるか判断できるよう、名前の先頭に目的に応じたプリフィクスを追加します。
目的の例 プリフィクスの例 何かを追加する add_ 何かを削除する del_ 何かを計算する calc_ 何かを移動する move_ 何かをセットする set_ 何かのテストにつかう test_
・意味のある名前について
aaaaaaaaaaaは最終的に必要?目的は? プログラミング学び初めの頃によくやってしまいがちなことの一つに、実験用の変数のような「瞬間的にほしい要素」に対し、一見して意味のない名前をつけるということがあります。
意味のない名前の例 a b c aaa bbb ccc gngingaio miewaaaaaa
※ループカウンターで使われる[i,j,k] や、座標を表現する際に使われる[x,y,z][u,v,w] などは、それ単体では意味のないアルファベットですが、一般的な名前として広く認知されているので、意味を持っています。
・名前の記法について
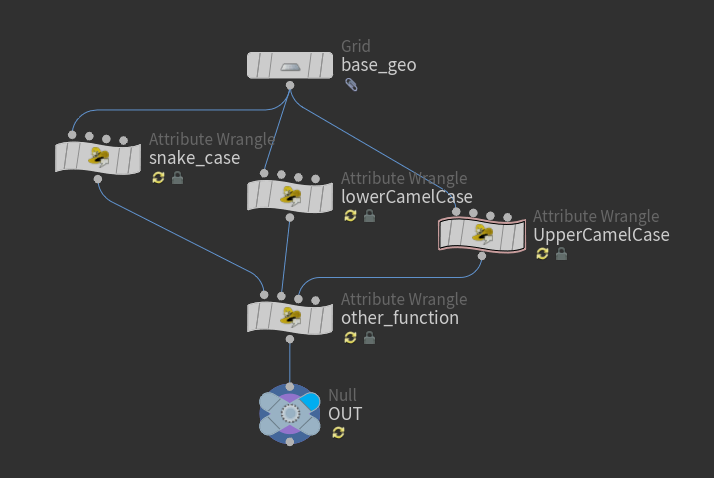
各種記法で記述したノード名のサンプル プログラミングで使われる名前の記法には いくつか種類があります。
スネーク記法 calc_cut_distance ローワーキャメル記法 calcCutDistance アッパーキャメル記法 CalcCutDistance
筆者は最近、Pythonのコード規約であるPEP8にならうことが多いです。
・略称について
略しすぎると、そのノードの役割が全くわからなくなります 名前付き要素に略称を使うことは可読性を損なう一因となります。
元の名前の例 略称名 略称名(悪い例) position pos ps, p point pt p attribute attr a, at, number num m, nm,
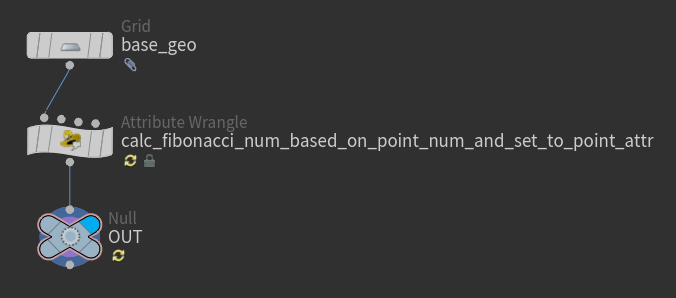
・長すぎる名前について
長過ぎる名前は、詳細はわかりますが不便です 名前の文字数は長くても20文字~30文字までといった意見をよく見かけます。 ですが、省略しすぎて意味が全くわからない名前よりは遥かに良いです。
・名前付けの具体例
上記を踏まえた上で、具体的な名付けの例を挙げてみます。
要素の目的や動作 名前の例 ポイントを追加するwrangle名 add_point primにsizeアトリビュートを追加するwrangle名 add_size_attr_to_prim 三角ポリゴンを削除するwrangle名 del_triangle_prims ループ数を格納する変数名 loop_num ポイント数を格納する変数名 point_num ベクトルAとBの内積を格納する変数名 dot_A_B
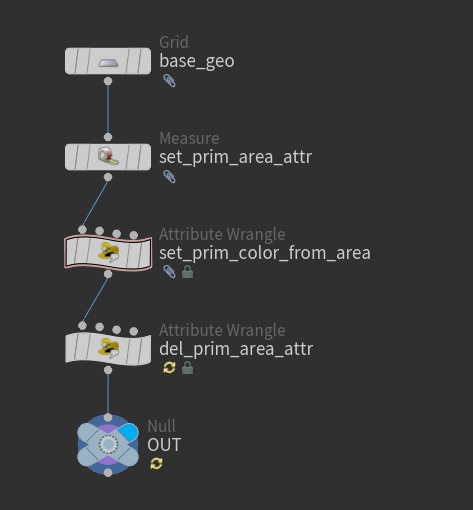
□アルゴリズムの更新とテスト
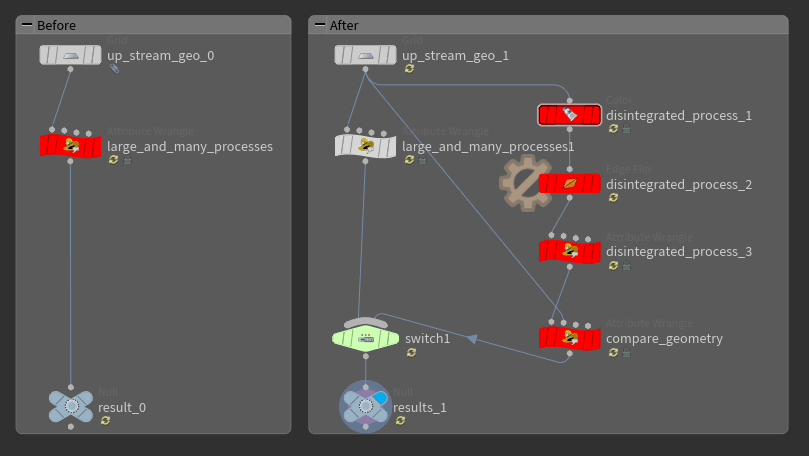
compare_geometryでunittestを行いながら処理を分解 リファクタリングの重要なポイントに、処理の内容を変えずに構造を整理するということを挙げました。
通常のプログラミングでのリファクタリングは以下のように進めます。
1 リファクタリング対象を複製し、もとのロジックをとっておきます。 2 リファクタリング後の処理がどうなっていれば正解なのか判断できるデータを作ります。 3 リファクタリング語の処理結果が、リファクタリング前と同じであることを確認しながら構造の修正を行います。 4 リファクタリングが完了し、もとの処理が必要なくなったら削除
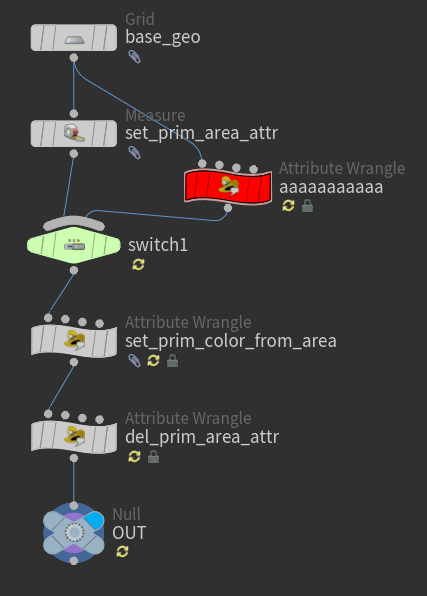
Houdiniの場合もこれによく似ていて、以下のように進めます
1 リファクタリング対象のノードや一連のノードチェーンを複製、分流。 2 Switch SOPを作成し、分流したノードの出力を接続します。 3 リファクタリング前後で結果が同じであることを確認しながら構造の修正を行います。 4 リファクタリングが完了し、もとの処理が必要なくなったら削除
□関心の分離
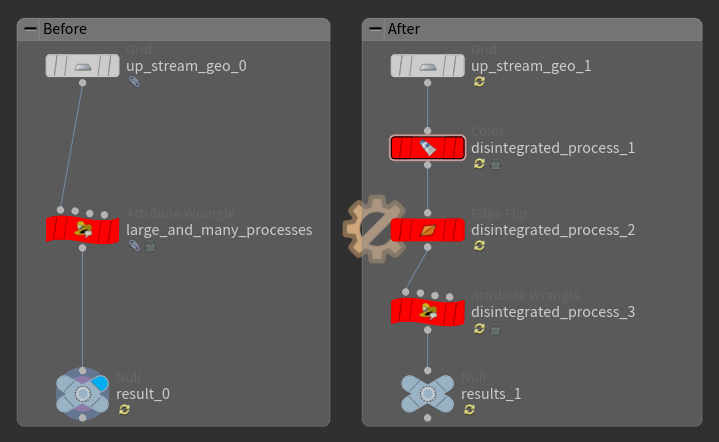
1つのWrangleに3種類の処理が含まれていたので分解した例 1つのノードでは、1度に1種類の処理のみを行うようにします。「関心を分離する」 ということです。
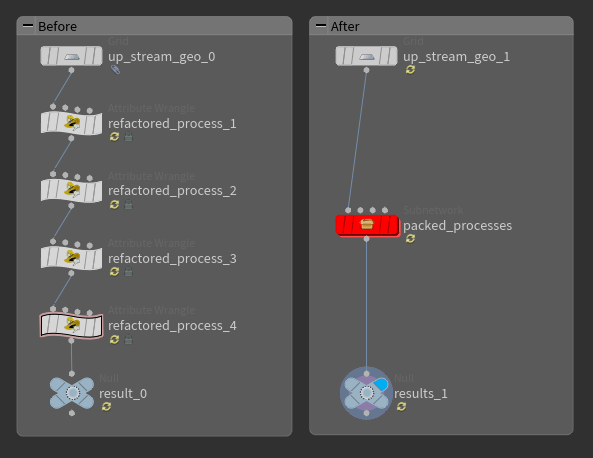
□処理の集約
整理された5つの処理を、1つのsubnetに集約した Houdiniに限らず一般的なプログラミングでは、複数の小さな処理を積み重ねて大きな処理を組み立てていきます。
□処理の再利用
一心不乱にノードネットワークを作成していると、途中で行ったコピー&ペーストの影響なども手伝い、全く同じ処理を随所で繰り返している事態に陥ることがあります。
・HDA
Subnetにまとめた仕組みは、デジタルアセットに変換することで再利用が簡単になります。(この方法については、多くの方が言及されているので、ここでは解説しません)
・Compiled Block/Invoke Compiled Block
同じ処理の一つCompiled Blockにまとめ Compiled Blockに対応しているノードだけで処理を構成する必要がありますが、Compiled Blockを使って一連の処理をひとくくりにし、Invoke Compiled Blockを通して、一連の処理を再利用できます。
他にも多くのリファクタリングテクニックがあるのですが、ここでは基本的なものに絞って紹介させていただきました。
最後に、個人的にリファクタリング関連で参考になったと感じる書籍をいくつか紹介します。