
■はじめに
この記事は、「Houdini Advent Calendar 2018 – 8日目」の記事です。
既存のノードネットワークを変更する際、変更する対象が巨大であるためにどこを変更すべきかわかりにくくなってしまっていたり、ある箇所への変更が他の箇所に影響してしまい、メンテナンスしづらい状況を経験したことは誰にでもあると思います。
この記事では、そのような状況を改善・予防するため「リファクタリング」と呼ばれる手法に焦点を当て、筆者の主観をもとに基本的な手法を紹介したいと思います。
■対象読者
・Houdini初級~中級者
・メンテナンスしにくいノードネットワークに日々苦しんでいる方
・メンテナンスしやすい設計でノードネットワークを構築したい方
・プログラミング初心者で、読みやすいコードを書くための作法を知りたい方
■リファクタリングとはなにか?
リファクタリング (refactoring) とは、コンピュータプログラミングにおいて、プログラムの外部から見た動作を変えずにソースコードの内部構造を整理することである。また、いくつかのリファクタリング手法の総称としても使われる。ただし、十分に確立された技術とはいえず、また「リファクタリング」という言葉に厳密な定義があるわけではない。(Wikipediaより抜粋)
※ここでいう「プログラムの外部から見た動作を変えず」というのは、リファクタリング前後で、リファクタリングする対象が行う処理の結果を変えないという意味です。
■Houdiniでのリファクタリング
Houdiniでの作業はプログラミング色が強く、ノードネットワークを組み立てることはプログラミングすることそのものと言えます。
ノードネットワークは、ある種ソースコードのようなものです。
更に、HoudiniではVEX/Wrangle/Pythonなど、プログラミングそのものを行う要素も含んでいます。
そのため「リファクタリング」手法のいくつかをHoudiniでも比較的素直に取り入れることができます。
■リファクタリングのメリット
リファクタリングにより、ノードネットワークの構造を整理することができ、結果として以下のようなメリットが得られます。
・ノードネットワークを局所的/全体的に理解しやすくなる
・ノードネットワークの修正(保守)が簡単になる
・ノードネットワークの拡張が簡単になる
・理解しやすく整理された形で新たなノードネットワークを作れるようになる
■手法ごとの具体的な方法
□名前の変更
ノード名、パラメータ名、アトリビュート名、Wrangleの変数名など、各種「名前付きの要素」を、誰が見てもわかりやすい形にリネームします。
これにより、その要素の役割が判断しやすくなり、時間が経ってから見直したときや、他人へデータを渡したときに処理の内容を理解する助けになります。
・名前のプリフィクス(接頭辞)について
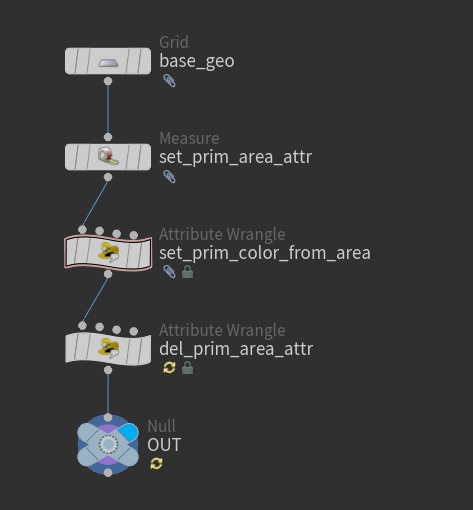
その要素が何を行うものであるか判断できるよう、名前の先頭に目的に応じたプリフィクスを追加します。
ルールに則ったプリフィクスを利用すると、ひと目でその要素が大雑把にどのような動作をするものか判断しやすくなり、メンテナンス性が向上します。
例えばノード名はそのノードの動作に適した動詞をプリフィクスにします。
変数名の場合も同様に、変数の役割がわかるようなプリフィクスをつけます。
このようにしておけば、ノードリストなどでノードを検索する際のヒントにもなります。
| 目的の例 | プリフィクスの例 |
| 何かを追加する | add_ |
| 何かを削除する | del_ |
| 何かを計算する | calc_ |
| 何かを移動する | move_ |
| 何かをセットする | set_ |
| 何かのテストにつかう | test_ |
・意味のある名前について
1年後に思い出せる気がしません・・・
プログラミング学び初めの頃によくやってしまいがちなことの一つに、実験用の変数のような「瞬間的にほしい要素」に対し、一見して意味のない名前をつけるということがあります。
これは、実験中はいいのですが、実験終了後にこの要素が不要となったにもかかわらず、要素を消し忘れたまま時間が経ってしまった時に問題を引き起こします。
このような要素は本来不要であるにもかかわらず、なんとなくまだ必要そうな気がしてしまい、出来上がった仕組みを壊してしまうことに対する恐れも手伝い、消せないまま放置してしまったことがある方は多いのではないでしょうか。
また、実験用に作った要素が最終的に採用され、利用されることになるケースもあります。
このような場合も、はじめから意味のある名前をつけておけば、名前を修正する手間が省けて一石二鳥です。
| 意味のない名前の例 |
| a b c |
| aaa bbb ccc |
| gngingaio miewaaaaaa |
※ループカウンターで使われる[i,j,k]や、座標を表現する際に使われる[x,y,z][u,v,w]などは、それ単体では意味のないアルファベットですが、一般的な名前として広く認知されているので、意味を持っています。
そのため、使用しても何ら問題ありません。
・名前の記法について
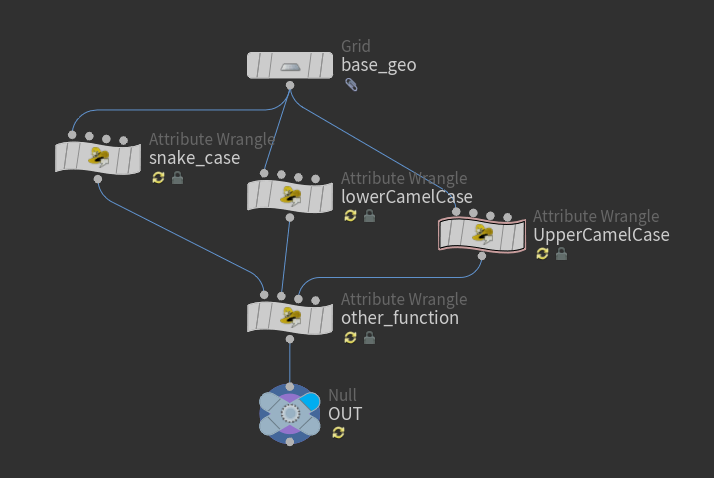
プログラミングで使われる名前の記法には いくつか種類があります。
よく目にする主な記法はだいたい以下の3通りだと思います。
| スネーク記法 全部小文字 単語の区切りをアンダーバーで区切る プログラミングでは主に変数名で使用 | calc_cut_distance point_num prim_area add_two_point |
| ローワーキャメル記法 名前の先頭は必ず小文字 単語の区切りごとに頭文字を大文字にする 主に変数名で使用 | calcCutDistance pointNum primArea addTwoPoints |
| アッパーキャメル記法 すべての単語の区切りごとに頭文字を大文字にする プログラミングでは主にクラス名で使用 | CalcCutDistance PointNum PrimArea AddTwoPoints |
筆者は最近、Pythonのコード規約であるPEP8にならうことが多いです。
具体的に言うと以下のようなルールに従っています。
・ノード名やプログラムの変数名はローワーキャメルケースで記述
・Pythonコード中のクラス名はアッパーキャメルケースで記述
・略称について

名前付き要素に略称を使うことは可読性を損なう一因となります。
メンテナンス性を高めるためには、極力名前のパーツに略称を使わないことが望ましいといえます。
例えば、あるノードを「calc_center_position」という具体的な名前にする場合を考えます。
このとき、「position」という言葉が長すぎると感じるかもしれません。
そのような場合、略称を使いたくなります。
しかし、ここで「position」を「p」と極端に略した場合、その「p」がどのような意味合いで選択された名前なのか第三者には瞬時に理解できません。(もちろん前後の文脈から想像はできますが、瞬時に理解するのは難しいでしょう)
もしかしたら、数日後の自分ですらその「p」が何なのか即答できないかもしれません。
そこで、この「position」という文字列を、一般的によく使われる「pos」という略称に置き換えるのは悪くない考えです。
ただし、前後の文脈によっては「pos」から「positive」など、別の言葉を連想する可能性もあり得るので、意味をはっきり伝えるという意味では少し確実性に欠けます。
とはいえ名前が長くなりすぎるのも困りものです。
実際のところ、若干の読みやすさを犠牲にして、明らかに一般的な共通認識として定着している略称のみを必要最小限の範囲で使用するのが良い落とし所となるでしょう。
| 元の名前の例 | 略称名 | 略称名(悪い例) |
| position | pos | ps, p |
| point | pt | p |
| attribute | attr | a, at, |
| number | num | m, nm, |
・長すぎる名前について
適度に略称を取り入れながら、ほどほどの長さに収めましょう
名前の文字数は長くても20文字~30文字までといった意見をよく見かけます。
確かに長い名前はコードが複雑化すると全体が見づらくなる原因になります。
ちょっとした文章のような長さの名前はおすすめできません。
ですが、省略しすぎて意味が全くわからない名前よりは遥かに良いです。
短すぎる名前を使うくらいなら、意味のわかる長い名前を使いましょう。
VEXやPythonの場合、Visual Studio CodeやSublimeなどに、対応する言語のプラグインをインストールして外部エディタとして利用すると、インテリセンス(コード補完機能)が使えるようになります。
Houdini内ではノードパスなどでインテリセンスが利用できます。
そのため、多少長い名前を使用していても間違いなく簡単に入力できるうえに、いざ名前が長すぎたと感じる場合でも、エディタの機能で特定の対象だけ簡単にリネームできるので、さほど問題になりません。
・名前付けの具体例
上記を踏まえた上で、具体的な名付けの例を挙げてみます。
| 要素の目的や動作 | 名前の例 |
| ポイントを追加するwrangle名 | add_point |
| primにsizeアトリビュートを追加するwrangle名 | add_size_attr_to_prim |
| 三角ポリゴンを削除するwrangle名 | del_triangle_prims |
| ループ数を格納する変数名 | loop_num |
| ポイント数を格納する変数名 | point_num |
| ベクトルAとBの内積を格納する変数名 | dot_A_B |
□アルゴリズムの更新とテスト
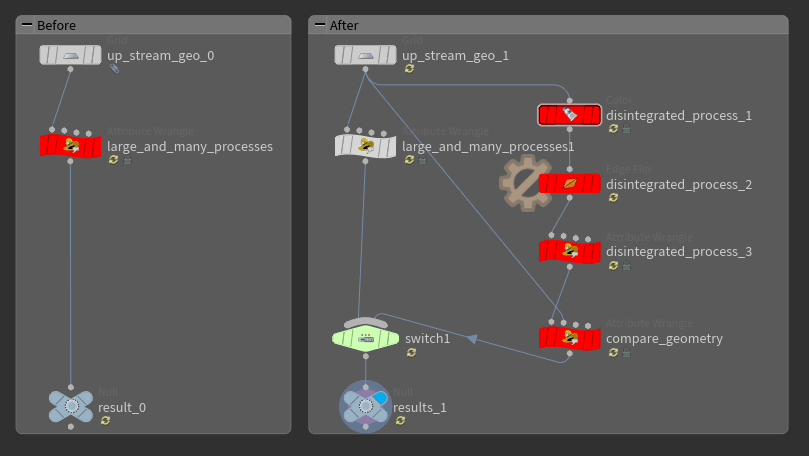
リファクタリングの重要なポイントに、処理の内容を変えずに構造を整理するということを挙げました。
そのためには、リファクタリングの前後で結果に差がないことを確認しながら作業をすることが重要です。
通常のプログラミングでのリファクタリングは以下のように進めます。
| 1 | リファクタリング対象を複製し、もとのロジックをとっておきます。 |
| 2 | リファクタリング後の処理がどうなっていれば正解なのか判断できるデータを作ります。 このデータを、リファクタリング後の処理結果と常時比較しながら、結果が異なる場合に即座に検知するために使います。 この比較は、一般的にユニットテストと呼ばれます。 |
| 3 | リファクタリング語の処理結果が、リファクタリング前と同じであることを確認しながら構造の修正を行います。 |
| 4 | リファクタリングが完了し、もとの処理が必要なくなったら削除 |
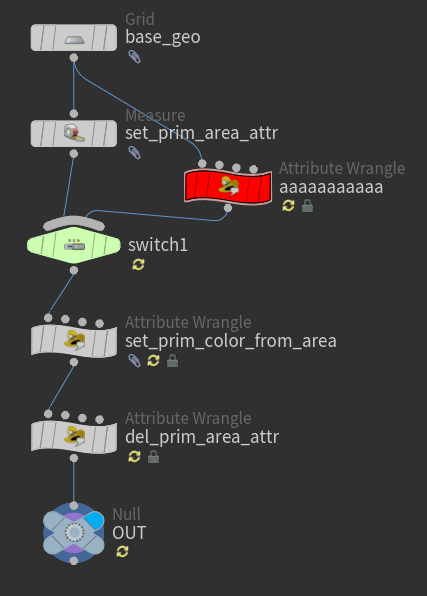
Houdiniの場合もこれによく似ていて、以下のように進めます
| 1 | リファクタリング対象のノードや一連のノードチェーンを複製、分流。 |
| 2 | Switch SOPを作成し、分流したノードの出力を接続します。 このSwitch SOPでリファクタリング前後の結果を簡単にスイッチして確認しやすくします。 ジオメトリのアトリビュートを比較するユニットテスト用HDAを作成してもいいでしょう。 |
| 3 | リファクタリング前後で結果が同じであることを確認しながら構造の修正を行います。 |
| 4 | リファクタリングが完了し、もとの処理が必要なくなったら削除 |
□関心の分離
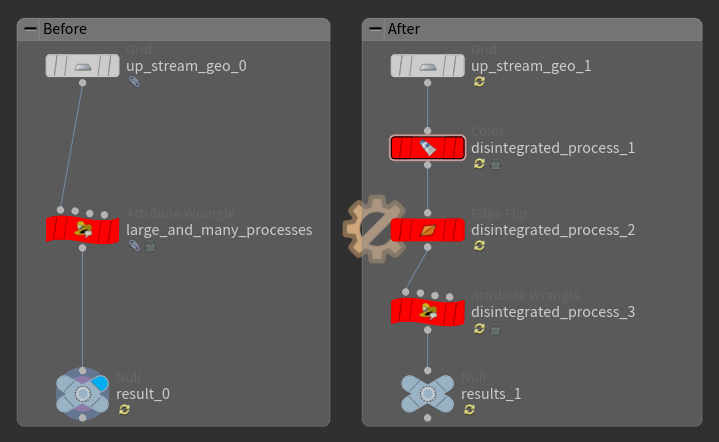
1つのノードでは、1度に1種類の処理のみを行うようにします。
例えば、色を設定するWrangle SOPでは色を設定することのみを行うようにします。
このWrangle SOPでは、色を設定すると同時に法線を設定するように複数種類の処理をさせることはしません。
色の設定と別に法線を設定する必要がある場合、2つの処理を切り分けて別々のノードを作成し、それぞれで処理を行います。
処理を切り分けることでその処理が影響する範囲が小さくなります。
これにより、この処理に対する何らかの変更が必要な場合に気を配る必要にある範囲が小さくなります。
これが「関心を分離する」ということです。
関心を分離した結果、それぞれの処理に変更を加えたい場合や、ある処理の前後に新たな処理を追加する場合に、変更すべき箇所がわかりやすくなります。
また、ノードを切り分ける場合は、処理のステップが複数のノードに分かれるので、各ノードのVisibilityフラグを切り替えながら、各処理ごとの結果が確認しやすくなります。
Wrangleの場合、コード中の特定の行で処理を止めて途中経過を確認するようなデバッグ機能がないので、Wrangleコードとそのコードで使われるパラメータを機能単位のWrangleに切り分けて関心を分離することになります。
□処理の集約
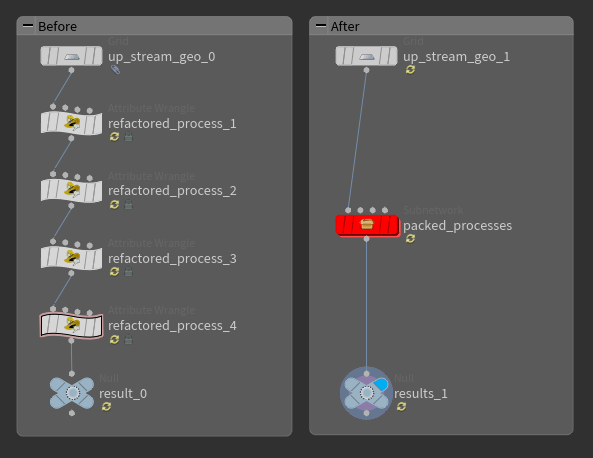
Houdiniに限らず一般的なプログラミングでは、複数の小さな処理を積み重ねて大きな処理を組み立てていきます。
Houdiniでは、複数のノードをSubnetノードにパックしてまとめることができます。
複数の小さな処理で成り立つ大きな処理をパックすることで、処理のくくりが明確になり、ノードネットワークの見通しが良くなります。
これは一見すると、上で挙げた「関心の分離」に反するように見えます。
たしかに、何も考えずにSubnetに複数のノードをまとめてしまうと、むしろノードネットワークが俯瞰しづらくなり、混乱の原因になります。
そのため、処理を集約する際は、必ず集約する処理に対し関心の分離を適用します。
複数の処理を一つのSubnetにまとめるタイミングは、関心の分離を適用する前でも後でも問題ありません。
関心の分離を適用するとノードが増えます。
すでにノードネットワーク全体が膨大なノード数で構成されていて、これ以上ノードを増やすと視覚的に全体を俯瞰しづらくなる場合などは、先に関心の分離を適用する処理の範囲をSubnetにまとめておき、そのSubnet内で適用することで、その他の箇所に気を取られずに作業できるようになります。
これもまた、ノードネットワーク全体を巨大な処理と見立てた関心の分離とも呼べます。
□処理の再利用
一心不乱にノードネットワークを作成していると、途中で行ったコピー&ペーストの影響なども手伝い、全く同じ処理を随所で繰り返している事態に陥ることがあります。
全く同じ処理が複数箇所にあり、それぞれの処理に同じ変更を加えたい場合、それぞれに対し個別に同じ変更を加えるのは現実的とは言えません。
このような場合、処理を切り出して再利用できるようにします。
その後、切り出した再利用可能な処理で各所の重複部分を置き換えることで、その後の処理変更が1箇所で行えるようになります。
・HDA
Subnetにまとめた仕組みは、デジタルアセットに変換することで再利用が簡単になります。(この方法については、多くの方が言及されているので、ここでは解説しません)
・Compiled Block/Invoke Compiled Block

Invoke Compiled Blockによって呼び出しながら再利用
Compiled Blockに対応しているノードだけで処理を構成する必要がありますが、Compiled Blockを使って一連の処理をひとくくりにし、Invoke Compiled Blockを通して、一連の処理を再利用できます。
他にも多くのリファクタリングテクニックがあるのですが、ここでは基本的なものに絞って紹介させていただきました。
タイムリミットも迫り記事も長くなってしまったので、より実践的なリファクタリングの実例紹介は別の機会に・・・
この記事について、なにかご質問や間違いがありましたら遠慮なくツッコミをいただけると助かります。
最後に、個人的にリファクタリング関連で参考になったと感じる書籍をいくつか紹介します。
Houdiniはそもそもプログラミングツールではないため、これらの書籍で紹介されるすべてのテクニックが適用できるわけではありませんが、多くの点で役立ちます。(今回ご紹介したリファクタリングや、Wrangle、Pythonでコーディングする際など)
特に「レガシーコード改善ガイド」の方は、古いコードのメンテナンスに際し起こりうる様々な問題ごとに適用できる、リファクタリングとテストを使うコード改善テクニックが紹介されています。
今回紹介したユニットテストを使う安全な開発方法(テスト駆動開発)も、こちらの書籍から着想を得ています。
興味のある方はぜひ読んでみてください。